MySQL(二)
因为内容太多了,所以将其拆分为以下内容
参考
https://www.bilibili.com/video/BV1NJ411J79W
https://www.runoob.com/mysql/mysql-tutorial.html
MySQL 数据管理
外键(了解)
【强制】不得使用外键与级联,一切外键概念必须在应用层解决。 说明:以学生和成绩的关系为例,学生表中的 student_id是主键,那么成绩表中的 student_id 则为外键。如果更新学生表中的 student_id,同时触发成绩表中的 student_id 更新,即为 级联更新。外键与级联更新适用于单机低并发,不适合分布式、高并发集群;级联更新是强阻 塞,存在数据库更新风暴的风险;外键影响数据库的插入速度。 ——阿里巴巴Java开发手册
DML(掌握)
where
| 操作符 | 描述 | 实例 |
|---|---|---|
| = | 等号,检测两个值是否相等,如果相等返回true | (A = B) 返回false。 |
| <>, != | 不等于,检测两个值是否相等,如果不相等返回true | (A != B) 返回 true。 |
| > | 大于号,检测左边的值是否大于右边的值, 如果左边的值大于右边的值返回true | (A > B) 返回false。 |
| < | 小于号,检测左边的值是否小于右边的值, 如果左边的值小于右边的值返回true | (A < B) 返回 true。 |
| >= | 大于等于号,检测左边的值是否大于或等于右边的值, 如果左边的值大于或等于右边的值返回true | (A >= B) 返回false。 |
| <= | 小于等于号,检测左边的值是否小于或等于右边的值, 如果左边的值小于或等于右边的值返回true | (A <= B) 返回 true。 |
如果我们想在 MySQL 数据表中读取指定的数据,WHERE 子句是非常有用的。
使用主键来作为 WHERE 子句的条件查询是非常快速的。
如果给定的条件在表中没有任何匹配的记录,那么查询不会返回任何数据。
增加
insert
1 | INSERT INTO table_name ( field1, field2,...fieldN ) |
修改
update
1 | UPDATE table_name SET field1=new-value1, field2=new-value2 |
删除
delete
1 | DELETE FROM table_name [WHERE Clause] |
truncate
1 | TRUNCATE TABLE table_name |
delete 与 truncate 的区别
- 相同点:都能删除表数据,不影响表结构
- 不同:
- TRUNCATE 重新设置自增(归零)
- TRUNCATE 不影响事务
DQL 查询数据
1 | select [all | distinct] <select_expr>, <select_expr>, ... |
简单示例
1 | select * from users -- 查询全部表数据 |
去重
1 | select distinct user_id from news -- 依据 user_id 去重 |
数据库的列
1 | select version() --查看数据库版本 |
逻辑运算
| 逻辑运算符 | 说明 |
|---|---|
| and && | 与 |
| or || | 或 |
| not ! | 非 |
模糊查询
| 运算符 | 语法 |
|---|---|
| is null | a is null |
| is not null | a is not null |
| between and | a between b and c |
| like | a like b |
| in | a in (b,c,d...) |
like:
%:0个或多个字符
_:1个字符
连接查询(join on)
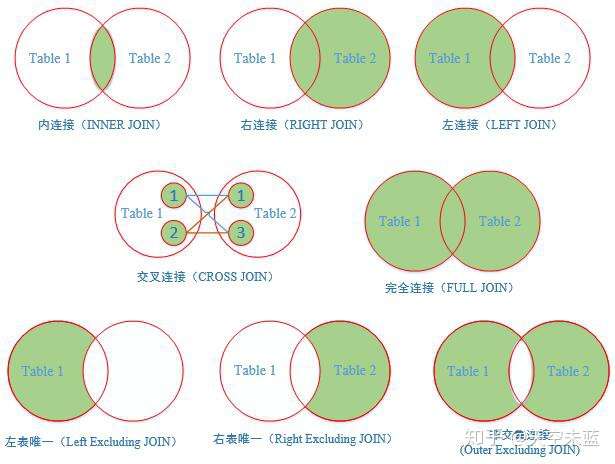
| 操作 | 说明 |
|---|---|
| INNER JOIN | 内连接,或等值连接,获取两个表中字段匹配关系的记录。 |
| LEFT JOIN | 获取左表所有记录,即使右表没有对应匹配的记录。 |
| RIGHT JOIN | 获取右表所有记录,即使左表没有对应匹配的记录。 |
例:
等值连接:查找两个表中连接字段相等的记录。
1 | --查询每个学生的学号、姓名、籍贯、年龄、专业、班级 |
自身连接:就是和自己进行连接查询,给一张表取两个不同的别名,然后附上连接条件。
1 | --要在学生表里查询与 HH 同龄且籍贯也相同的学生信息 |
参考:https://zhuanlan.zhihu.com/p/68136613
子查询、嵌套查询
- 格式1
1 | select <select_expr> from (<select_statement>) <sq_alias_name>; |
- 格式2
1 | select (<select_statement>) from <table_name>; |
参数说明
- select_expr:必填。格式为
col1_name, col2_name, 正则表达式,...,表示待查询的普通列、分区列或正则表达式。 - select_statement必填。子查询语句。如果子查询语句为格式2,子查询结果必须只有一行。格式请参见SELECT语法。
- sq_alias_name:必填。子查询的别名。
- table_name:必填。目标表名称。
分组
[group by 子句 ]:分组子句,group by子句主要的作用是分组,从而进行统计操作,而不是为了展示(展示的时候,只会展示分组记录的第一条记录),分组时,一般会结合使用count()、max()、min()、avg()、sum()函数。
例:
1 | select c_id,sex,count(*),max(height),min(height),avg(height),sum(age),GROUP_CONCAT(name) from my_student group by c_id ,sex; |
[having 子句]:having的作用类同where,而且having能做几乎所有where能做的事情,而where却不能做having能做的很多事情,主要是因为
where只能在磁盘提取数据的时候对数据进行操作;而在内存中对数据进行group by分组之后的结果进行处理,只能通过having。
例:
1 | select c_id,count(*),max(height),min(height),avg(height),sum(age) from my_student group by c_id having COUNT(*) >= 3; |
排序
升序 ASC
降序:DESC
1 | ORDER BY order_experssion[ASC | DESC] |
其中,order_experssion表示用于排序的列或列名及表达式。当有多个排序列时,每个排序了列用逗号隔开,而且列后都可以跟一个排序要求。
分页
一般的分页查询
一般的分页查询使用简单的 limit 子句就可以实现。limit 子句声明如下:
1 | SELECT * FROM table LIMIT [offset,] rows | rows OFFSET offset |
LIMIT 子句可以被用于指定 SELECT 语句返回的记录数。需注意以下几点:
- 第一个参数指定第一个返回记录行的偏移量,注意从
0开始 - 第二个参数指定返回记录行的最大数目
- 如果只给定一个参数:它表示返回最大的记录行数目
- 第二个参数为 -1 表示检索从某一个偏移量到记录集的结束所有的记录行
- 初始记录行的偏移量是 0(而不是 1)
例:
1 | select * from news limit 0,5 |
子查询优化
参考
因为内容太多了,所以将其拆分为以下内容