置顶声明
博客停更了
因为个人博客运营比不上现如今的微信公众号等等渠道,所以今后所有内容统一更新在微信公众号和语雀中。
个人语雀:wnhyang
共享语雀:在线知识共享
Github:wnhyang - Overview

因为个人博客运营比不上现如今的微信公众号等等渠道,所以今后所有内容统一更新在微信公众号和语雀中。
个人语雀:wnhyang
共享语雀:在线知识共享
Github:wnhyang - Overview
项目地址:https://github.com/wnhyang/coolGuard
如果对此此项目还不了解可以先看下面两篇文章
正如前文所讲,开始分支开发了,规划中main对应开源主分支(功能有限),pro对应标准付费分支,当然未来可能还会有pro-max🥳,demo对应在线体验分支,目前是基于pro增加一些限制和不一样的东西。
所以在线体验版本并不是开源版,会有些差别。
在开始之前还是先回顾一下最近做的事情吧!
最近除了在main分支做优化更新外,还要在pro分支做规划中的事情,说起来是这么概括就够了,但是其实事情很多,不仅是前端后端项目的迭代优化,更重要还有除编程外的其他事情。
其中花费时间最多的是在做开放在线体验上,因为这并不是简简单单的将服务部署在公网上这么简单的事,不过回头来看好像也就是这么简单的事情😂
因为放在公网上总要考虑很多安全性上的问题,记得之前买的服务器因为配置了常用安全组,并设置了简单的密码导致服务数据全没了,收到了“比特币换数据的要挟”,不过还好那台服务器就是自己随便玩玩的,没什么重要数据。除了数据问题之外,更有甚者被黑客攻击后被作为挖矿服务器,频繁高CPU,并收到云厂商的告警通知法律法规发现挖矿脚本要本人确定,挺麻烦的。自那之后,在这方面就谨慎起来了,不管是开发测试,密码都尽可能设置的复杂一些🥲怕了怕了
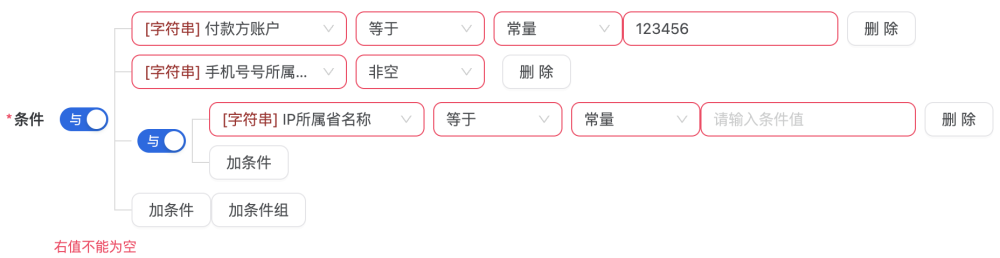
完善表单校验,对于普通的字段的校验相对简单,对于系统中如复合条件的校验也做了加强。
左/逻辑判断/右,递归等等。


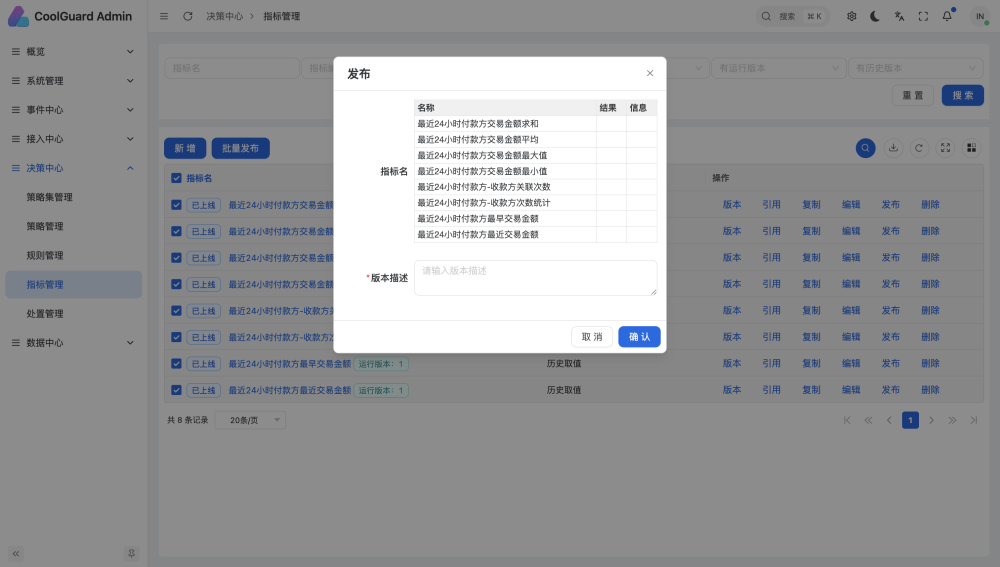
抽象了发布组件,新增批量发布组件
事件数据存储在ElasticSearch中,相关代码也只写在pro分支。
这部分重点在于ES索引的设计与检索数据的实现。
如下是目前事件数据页,支持复杂多条件查询
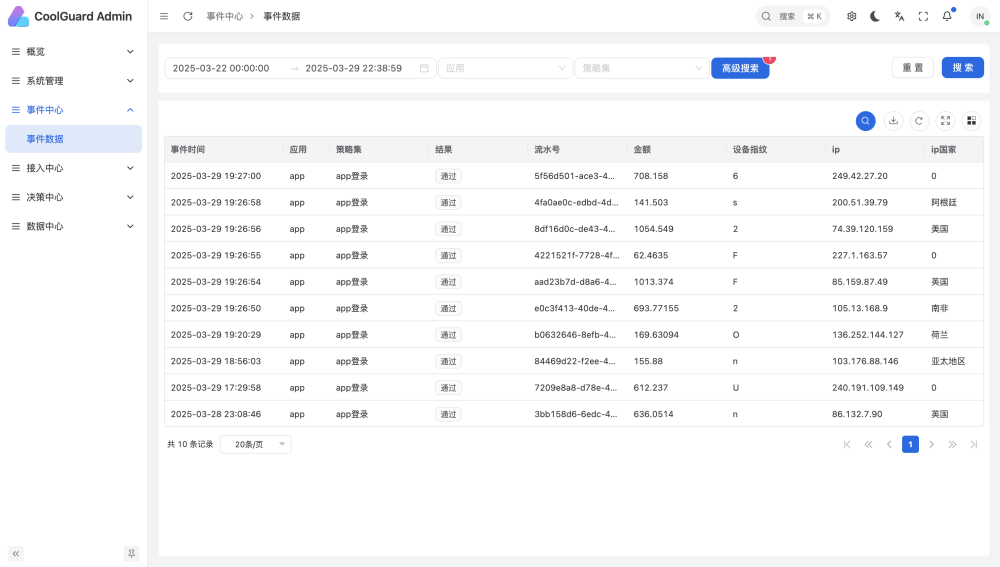
因为决策流配置还未完成,在面对多策略结果时,如何综合所有结果还在考虑中,所以目前所有结果都是“通过”。

同样高级搜索这里做了校验
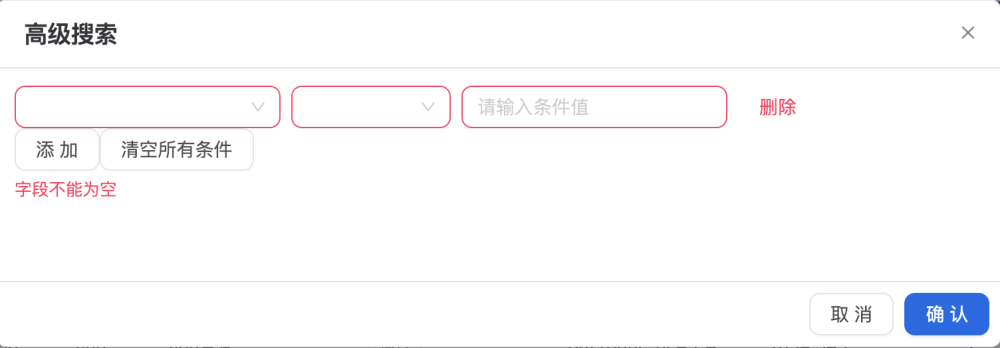
点击行即可看事件详细数据
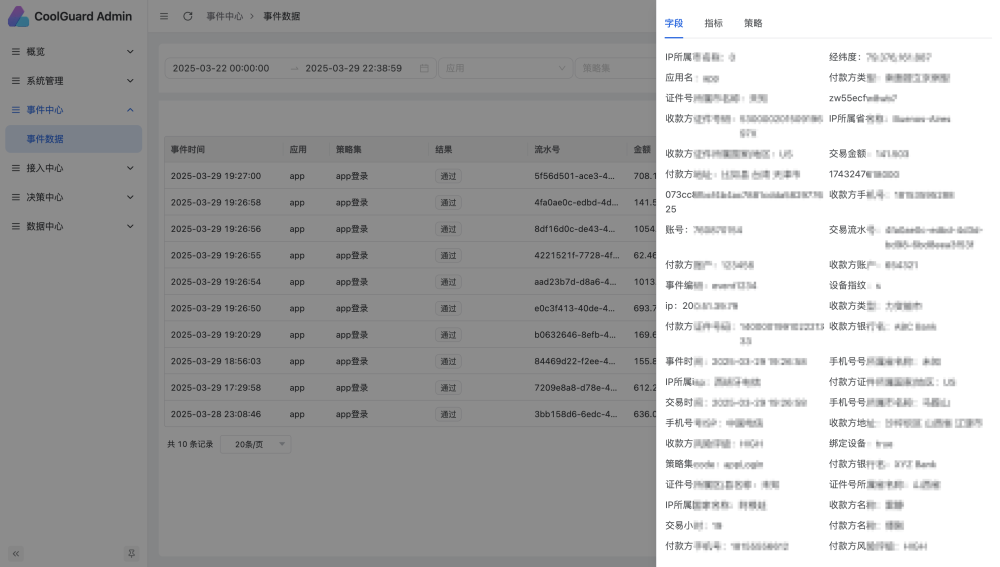
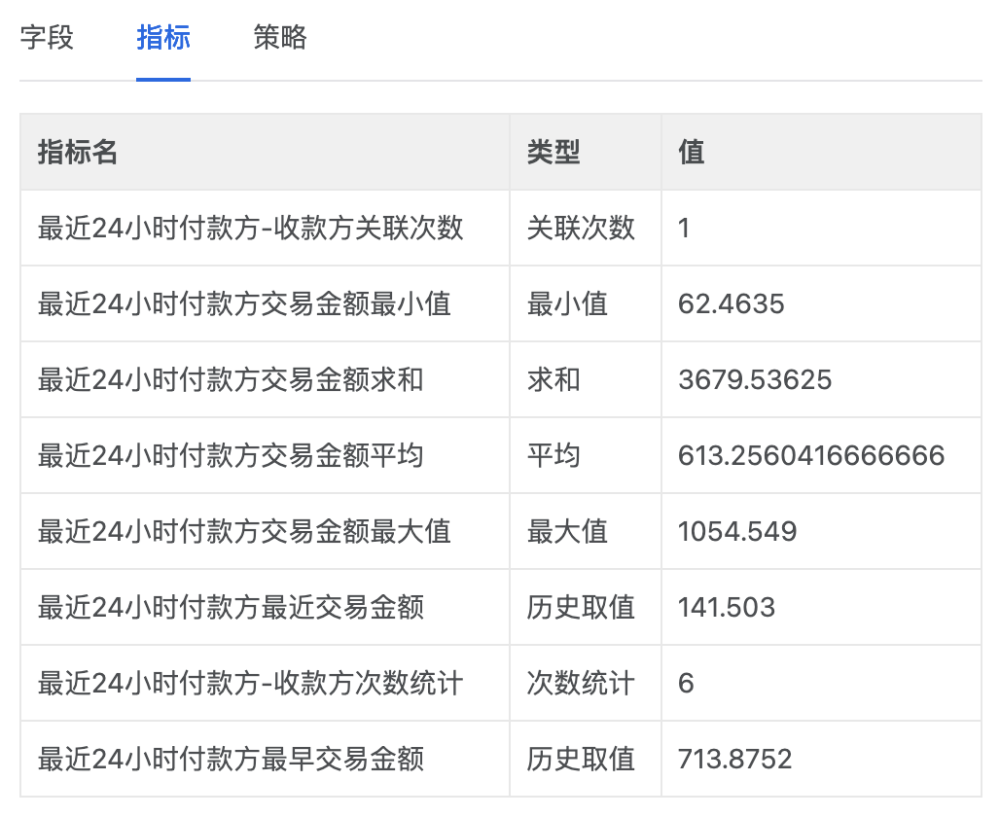
字段-指标-策略
上篇预热在线体验的文章也有展示
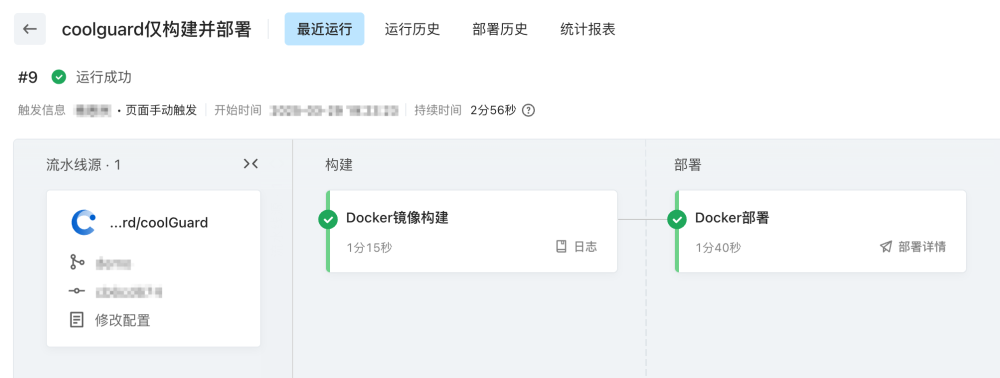
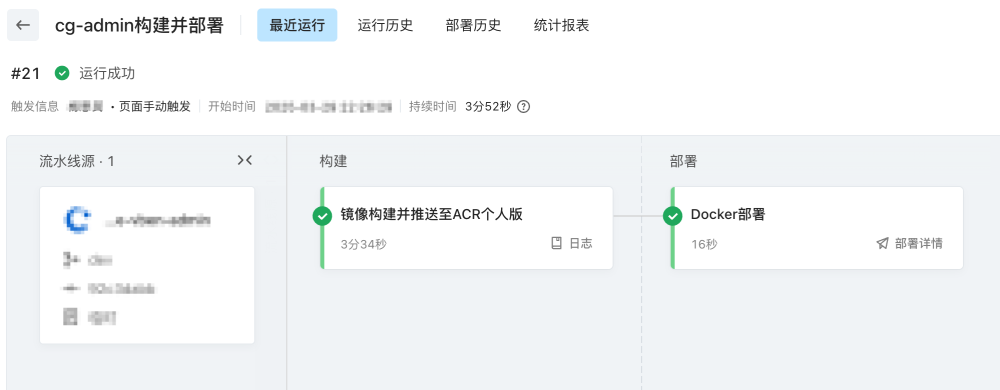
项目使用了云效的devops,采用Docker镜像部署方案,详细的如Dockerfile和docker-compose.yaml可以另开一篇文章讲。
要开放在线体验势必要考虑安全问题,包含服务器、中间件、账号、接口等等。
后端项目也为一些接口增加了权限校验,在线体验一定会限制的!
自己写的当然最为熟悉,对于目前有哪些问题,下一步怎么做,我是有比较清晰的规划的,但还是那句话,没有那么多时间精力啊🤪
除了大方向的功能/流程/交互方式/表/接口等等,更细节的如使用什么组件,那个方法需要优化,大概什么样式都是考虑中的,这些平常都记录在我的todolist中,每完成一项就删除一项,或者迁移到产品说明书/备忘录中。

关注公众号,私信或是加好友后,说明“在线体验”就好。
我会分配一个专有账号,此账号会有权限限制(这当然是必须的,主要是一些查询和新增的权限,修改、删除等等是没有),而且账号默认有效期只有7天。
如果人员过多,我会设置几个公用的账号(因为设置了同账号不允许多地登录,所以有挤掉的情况😅)。
毕竟是自费服务器,还是要限制一下。
当然这些只是此刻的规划,未来可能需要申请填写个人或公司信息、目的等等,也不一定,也有可能什么时候就关闭在线体验也不一定🙂↔︎️
关于反馈问题的渠道,当然私信和私聊都是可以的。
群聊的话,一直都没有,但如果开放在线体验了,想发一些公告,如:“维护中不可访问”,那么群聊就很有必要了。关于这个请看下面“交流群”。
关于系统如何工作的前面有很多文章了,不想在这里赘述了,未来尽量去补充详细的官方文档(产品、技术),敬请期待吧。
1、接口
每配置一个接入就有三个接口可用,/test、/sync、/async如下,test需要登录,sync适合需要决策的场景,async不会决策。
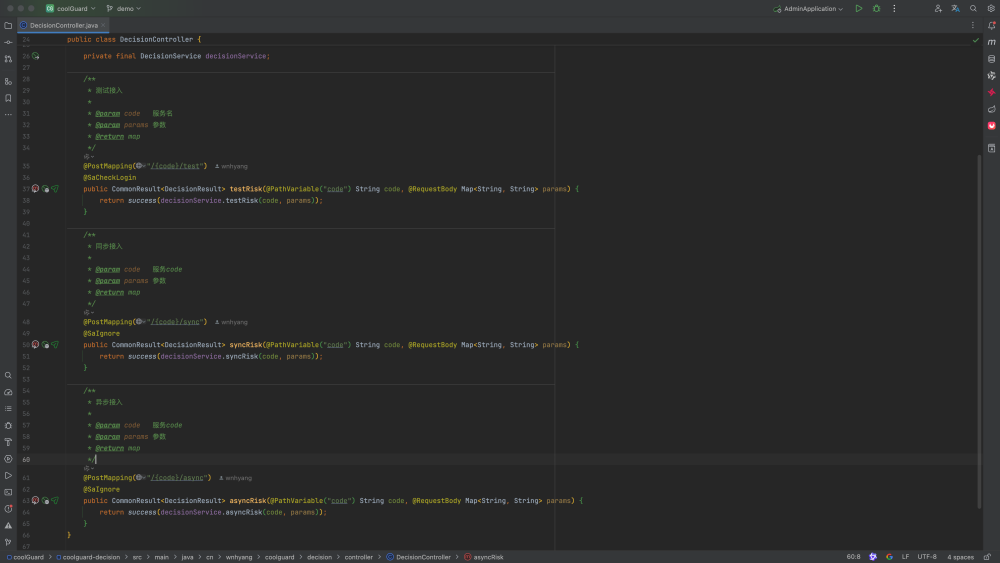
2、参数
接口参数就是下图配置的这些
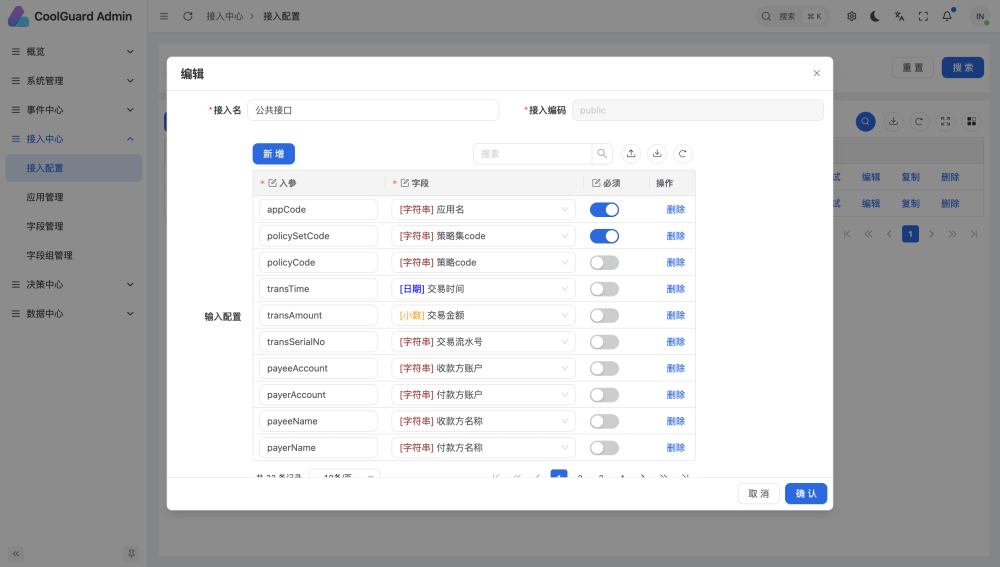
在线体验中配置了已经一个策略,发送时注意必须的几个字段就行,如下
1 | { |
平常我都是使用下面这种方式发的
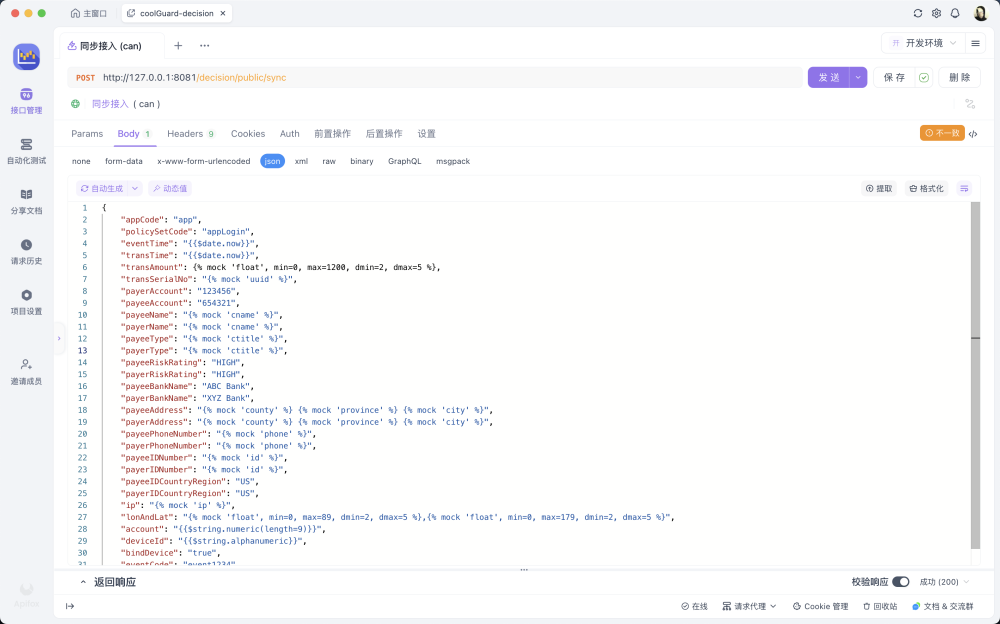
curl参考,mock的数据
1 | curl --location --request POST 'http://127.0.0.1:8081/decision/public/sync' |
3、响应
响应结果自己试一下吧。
服务器日志大概如下,目前影响耗时也还好。
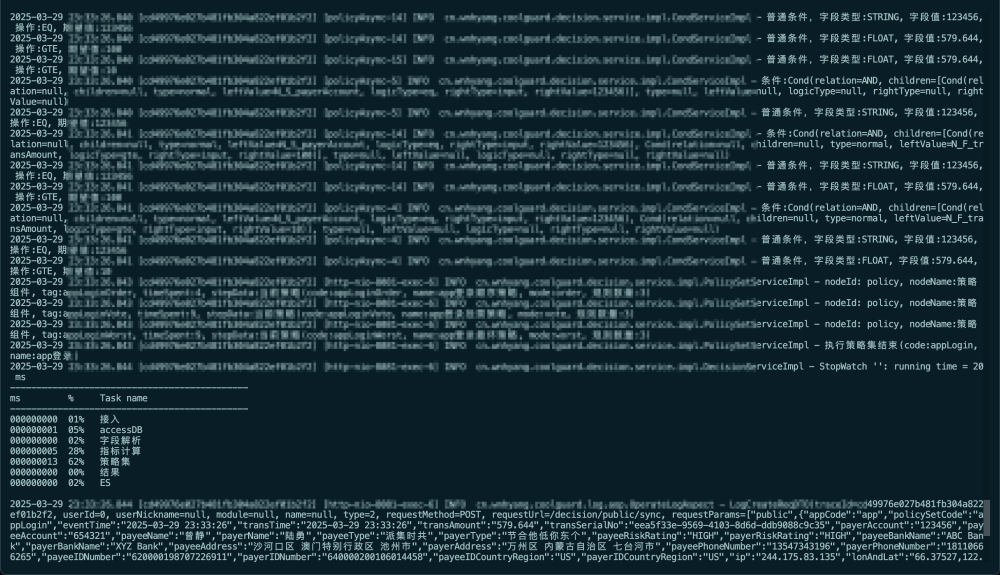
从决策的角度来看,这一步已经结束了,接下来就是调用方如何使用决策结果了,当然反馈机制也是需要的。
4、验证
参考前面的事件数据查看是否符合规则配置,是否按照策略运行。
交流群其实我是比较推荐qq频道的,因为几点
成员数量上限高
无论加入时间,历史消息可见
不仅仅是聊天,还有帖子
等等
交流群可作为官方通知,因为公众号是有消息限制的,所以这种交流群是最好的,另外可以听到大家的声音,有利于我们的共同成长
至于共同开发/运营,也还在考虑中。
不管是开放在线体验还是交流群都是需要精力去运营的,个人精力实在有限,我也想把一天掰开来用,还想拔几根毫毛生成几个分身呢🥹但实在是没空啊!
开源版大概就是修修补补了,pro应该会成为未来主要重心。
全局
规则引擎可以应用于哪些系统,用户画像、触达、风控、推荐、监控...
策略/规则篇
指标篇
风控系统指标计算/特征提取分析与实现01,Redis、Zset、模版方法
数据篇
远程接口调用模式
数据源批量同步模式
本篇只展开远程接口调用模式,以地理信息数据服务举例,重点分析高德和天地图。
这里指的就是高德和天地图,其作为供应商,同时也是数据源。
如在高德开发平台(天地图也是按应用分的),会以应用纬度再划分,同时服务是多种的。据此可以抽象供应商(供应商id、供应商名称、应用、应用密钥、合同编号、合同其他信息等等)。
供应商对多个应用,高德和天地图是一致的,但是下面服务就不一致了,天地图所有服务密钥就是应用密钥,高德是应用下新建服务后服务密钥是独立的。
每种服务对应不同的接口和请求响应配置。
https://lbs.amap.com/api/webservice/guide/api/georegeo
http://lbs.tianditu.gov.cn/server/geocoding.html
那么可以抽象服务(服务id、供应商id、服务类型、请求方法、请求路径、请求头、参数、请求体、超时时间、重试策略),当然所有这些都可以硬编码实现,但是本篇目标是抽象通用设计方案,用于后面的灵活配置。
套餐与服务是关联的,通常模式有每天/月/年免费额度,超量阶梯计费,包年/季/月等。
作为服务调用方,出于成本的考虑,费用当然相当关键,但是不同服务商的套餐与计费模式又不是那么容易抽象统一,从另一方面来讲灵活的服务调用(包含降级、重试策略等)只需关心接口相关的配置就好了,至于具体的费用,我比较建议不做,首先增加了复杂度,另外高德这样的三方数据服务商都会有开放平台,提供控制台用于服务的管理、流量分析、费用结算等等功能,非常丰富,作为服务使用方最好数据调用明细记录就已经不错了。
就像dify、coze的工作流编排时,重点是接口的配置,而不是数据服务商和费用的管理(当然不是说这些不重要)。
缓存除了可以是接口的配置,如请求体配置模版外,还可以是具体的三方数据缓存,当然这个要慎重,一致性和资源问题要考虑清楚了。
其实不管是上面讲的流量治理(降级、熔断、重试、超时、限流等等)和预警都是通用型设计,是现代高可用服务必然考虑的事情。
AI设计方案仅供参考
supplier)新增字段| 字段名 | 类型 | 说明 |
|---|---|---|
| billing_mode | ENUM('FREE_TIER','PAY_AS_YOU_GO','SUBSCRIPTION') | 计费模式(免费/按量/包月包年) |
| free_quota | INT | 每月免费额度(次数/数据量) |
| circuit_breaker | JSON | 熔断配置(失败率阈值、降级策略) |
supplier_plan)| 字段名 | 类型 | 说明 |
|---|---|---|
| plan_id | VARCHAR(36) | 套餐ID(主键) |
| supplier_id | VARCHAR(36) | 关联供应商 |
| plan_type | ENUM('MONTHLY','YEARLY') | 包月/包年 |
| price | DECIMAL(8,2) | 套餐价格 |
| max_requests | INT | 套餐内最大请求次数 |
| validity_days | INT | 有效期(天) |
price_config)扩展| 新增字段 | 类型 | 说明 |
|---|---|---|
| tiered_pricing | JSON | 阶梯计价规则(如 [{ "min": 1000, "price": 0.1 }]) |
| currency | VARCHAR(3) | 货币类型(如CNY、USD) |
user_subscription)| 字段名 | 类型 | 说明 |
|---|---|---|
| subscription_id | VARCHAR(36) | 订阅ID(主键) |
| account_id | VARCHAR(36) | 关联用户账户 |
| plan_id | VARCHAR(36) | 关联供应商套餐 |
| start_date | DATE | 订阅开始日期 |
| end_date | DATE | 订阅结束日期 |
| used_quota | INT | 已使用额度 |
api_config)| 字段名 | 类型 | 说明 |
|---|---|---|
| config_id | VARCHAR(36) | 配置ID(主键) |
| supplier_id | VARCHAR(36) | 关联供应商 |
| api_method | VARCHAR(20) | 接口方法(如GET_DATA) |
| http_method | ENUM('GET','POST') | 请求方法 |
| path | VARCHAR(100) | API路径(如/v1/data) |
| headers | JSON | 固定请求头(如{"Authorization": "Bearer {token}"}) |
| body_template | JSON | 请求体模板(支持变量插值) |
| timeout_ms | INT | 超时时间(毫秒) |
| retry_policy | JSON | 重试策略(次数、间隔) |
api_param)| 字段名 | 类型 | 说明 |
|---|---|---|
| param_id | VARCHAR(36) | 参数ID(主键) |
| config_id | VARCHAR(36) | 关联API配置 |
| param_name | VARCHAR(20) | 参数名 |
| param_type | ENUM('STRING','NUMBER','BOOLEAN') | 参数类型 |
| required | BOOLEAN | 是否必填 |
| default_value | VARCHAR(50) | 默认值 |
cache_config)| 字段名 | 类型 | 说明 |
|---|---|---|
| cache_key | VARCHAR(36) | 缓存键(主键) |
| supplier_id | VARCHAR(36) | 关联供应商 |
| api_method | VARCHAR(20) | 接口方法 |
| ttl_seconds | INT | 缓存有效期(秒) |
| key_pattern | VARCHAR(100) | 缓存键生成规则(如data:{param1}:{param2}) |
cache_data)| 字段名 | 类型 | 说明 |
|---|---|---|
| cache_id | VARCHAR(36) | 缓存ID(主键) |
| cache_key | VARCHAR(100) | 完整缓存键 |
| data | LONGTEXT | 缓存数据(JSON/文本) |
| expires_at | TIMESTAMP | 过期时间 |
| last_used | TIMESTAMP | 最后访问时间 |
alert_rule)| 字段名 | 类型 | 说明 |
|---|---|---|
| rule_id | VARCHAR(36) | 规则ID(主键) |
| trigger_type | ENUM('ERROR_RATE','LATENCY','BALANCE') | 触发类型(错误率/延迟/余额) |
| threshold | DECIMAL(5,2) | 阈值(如错误率>5%) |
| severity | ENUM('WARNING','CRITICAL') | 严重级别 |
| notify_channel | JSON | 通知渠道(邮件、钉钉、短信) |
alert_log)| 字段名 | 类型 | 说明 |
|---|---|---|
| alert_id | VARCHAR(36) | 预警ID(主键) |
| rule_id | VARCHAR(36) | 关联预警规则 |
| trigger_value | DECIMAL(10,2) | 触发时的实际值(如错误率6%) |
| triggered_at | TIMESTAMP | 触发时间 |
| resolved | BOOLEAN | 是否已处理 |
fallback_policy)| 字段名 | 类型 | 说明 |
|---|---|---|
| policy_id | VARCHAR(36) | 策略ID(主键) |
| supplier_id | VARCHAR(36) | 关联供应商 |
| condition | JSON | 触发条件(如连续失败3次) |
| fallback_type | ENUM('DEFAULT_DATA','BACKUP_API') | 降级类型(返回默认数据/切换备用接口) |
| backup_api_id | VARCHAR(36) | 备用接口ID(若降级类型为备用接口) |
| default_data | JSON | 默认返回数据 |
circuit_breaker_log)| 字段名 | 类型 | 说明 |
|---|---|---|
| log_id | VARCHAR(36) | 日志ID(主键) |
| supplier_id | VARCHAR(36) | 供应商ID |
| trigger_reason | VARCHAR(50) | 触发原因(如错误率超限) |
| triggered_at | TIMESTAMP | 触发时间 |
| restored_at | TIMESTAMP | 恢复时间 |
supplier_plan.supplier_id →
supplier.supplier_idapi_param.config_id →
api_config.config_idfallback_policy.backup_api_id →
api_config.config_idsupplier_id、api_method、triggered_atapi_request_log、alert_log)进行分区。api_request_log)和低频配置表。user_subscription剩余额度 →
若超出免费额度,按price_config阶梯价扣费 →
记录billing_detail并更新balance_transaction。circuit_breaker熔断 →
查询fallback_policy →
返回default_data或调用backup_api_id备用接口。cache_config.key_pattern生成缓存键 →
查询cache_data →
若命中且未过期,直接返回数据;否则调用三方接口并缓存结果。为什么会有这篇文章,当然还是离不开此项目https://github.com/wnhyang/coolGuard
因为这是计划中的一部分,而且不可或缺。
https://www.woshipm.com/it/5662657.html
https://www.woshipm.com/it/4269498.html
https://www.cnblogs.com/hole/p/16349359.html
https://zhuanlan.zhihu.com/p/515516955
https://zhuanlan.zhihu.com/p/461217285
https://www.tongdun.cn/product/xhbigdata
包含AI辅助创作!!!
在数据驱动的商业生态中,三方数据(即企业外部第三方机构提供的数据)已成为企业突破信息孤岛、实现精准决策的关键资源。面对数据量指数级增长与合规要求的日益严苛,构建高效、安全的三方数据管理体系,不仅是技术挑战,更是企业获取竞争优势的战略选择。
核心价值
关键挑战
供应商资质审核:
合同管理与SLA:
套餐:
计费:
API权限控制:
API版本管理:
动态请求模版:
缓存预热机制:
智能缓存策略:
多维度阈值预警:
降级策略:
熔断策略的动态调整:
数据清洗规则管理:
数据质量报告:
数据回溯机制:
审计日志管理:
安全策略版本管理:
数据脱敏:
AI赋能数据治理
区块链数据共享
跨行业生态融合
三方数据管理已从单一的技术问题演变为企业数字化战略的核心。通过构建模块化技术体系、拥抱AI与区块链创新,并建立跨行业协作机制,企业不仅能有效应对安全、质量、合规挑战,更能释放数据协同价值,在数字化竞争中构建可持续优势。
《风控要略:互联网业务反欺诈之路 (马传雷,孙奇,高岳)》第8章
 ## 一、核心概念
## 一、核心概念
指标定义:在风控反欺诈业务中,无论是基于专家规则还是风控模型,都需要依赖对一定时间范围数据进行回溯加工的变量,这些变量被称为指标。例如“1天内设备上登录的账户过多”这一规则,就需要回溯24小时的历史数据,计算该设备在这段时间内登录的账户个数,并与配置的阈值进行比较判断。
指标类型:
指标特征:
在前文免费使用满血版DeepSeek-R1的多种方案中已经对大语言模型(LLM)应用开发平台有了相关介绍了,如下:
以 Dify 为代表的生成式 AI 应用平台,具备以下显著特性,为 AI 应用开发带来了新的变革:
阿里TTL:https://github.com/alibaba/transmittable-thread-local
TLog:https://tlog.yomahub.com/
推荐阅读:https://tlog.yomahub.com/pages/5b7bd2/,本篇文章也是看了TLog的官方文档和相关源码而产生的。
在微服务架构中,由于线程池复用、异步调用等机制的存在,传统的线程级日志标识(如ThreadLocal)会导致请求链路断裂。例如,当主线程将任务提交到线程池时,子线程无法自动继承主线程的上下文信息,使得日志中的traceId丢失。
Log4j2的Mapped Diagnostic Context(MDC)通过ThreadLocal存储线程级上下文数据。例如,在HTTP请求进入时,通过拦截器将traceId存入MDC,日志模板中通过%X{traceId}动态替换值。
阿里的TTL组件解决了线程池场景下的上下文传递问题。通过装饰线程池,TTL在任务提交时自动拷贝父线程的上下文到子线程,并在任务结束后清理副本,确保多级线程池调用链路完整。
在log4j2.xml中配置PatternLayout,添加%X{traceId}占位符即可实现日志标识嵌入。
1 | <Property name="LOG_PATTERN" value="%d{yyyy-MM-dd HH:mm:ss.SSS} [%X{traceId}] [%t] %-5level %logger{36} - %msg%n"/> |
再次说明,此项目还在开发中,还有很多事情要做,并不完善。回想起来,我也觉得挺不可思议的,最开始只是尝试着做,想着把后端做的差不多就行了,可做着做着,愈发确信前端是必不可少的,也因此项目发展到了现在的地步。可以从Github的commit看出来,也是最近半年比较活跃,也是这期间,学到的最多,进展比较快。
本篇文章主要围绕着规则条件与操作、名单&标签&消息模版的管理。
再强调一下,开发版本不代表最终成品。
还是回顾一下之前讲的,规则就是IF(x){a}ELSE{b},其中x为条件,a和b是动作/操作。在规划中,条件不仅仅是简单的普通类条件,还有指标、名单、正则、脚本等,最近也完善了这部分。开始之前我必须要从名单&标签&消息模版说起,方便下面的规则操作展开。
排名不分先后
1、DeepSeek官方:https://chat.deepseek.com/,支持网页端与 APP 端使用
2、腾讯元宝:https://yuanbao.tencent.com/chat,支持网页端与 APP 端使用
项目地址:https://github.com/wnhyang/coolGuard
基于规则引擎的风控决策系统,旨在为企业提供高效、灵活且可扩展的风险控制解决方案。
以下是终极目标,部分已经实现,部分未实现,开源版本不会包含所有功能
实时指标计算,同步决策,异步决策,反馈
普通字段与动态字段:普通字段支持字符串、整数、小数、日期、布尔值、枚举,动态字段通过普通计算计算而来,高度可配置
数据接入:灵活配置数据接入的入参和出参
指标:基于时间计算的指标,目前已有:求和、次数统计、最大值、最小值、平均值、关联次数、历史取值,未来计划加入:移动距离、移动速度、趋势、方差、标准差、业务链、连续次数(不同与次数统计,中间插入其他状态则重新统计)、公式等
规则:条件支持:普通条件、指标条件、名单条件、正则条件、公式/脚本条件,动作支持:添加标签、添加名单、设置字段、发送消息,可设置正式和模拟状态
策略:模式分为:顺序模式、最坏模式、投票模式、权重模式
策略集:编排策略,是规则引擎核心作用的体现
指标、规则、策略、策略集版本管理
事件中心:事件数据分析、可视化、报表
豁免管理:配置式豁免决策,临时通行
数据服务:名单、标签、IP/证件号/经纬度/手机解析
三方集成:将三方以配置的方式接入系统
流量治理:熔断、限流、降级
监控中心:指标/规则/策略/执行、结果、效率监控等
系统管理:用户管理、角色管理、权限管理、日志管理、系统配置等
高级实验特性:A/BTest、冠军挑战、回测、仿真、模型、图谱分析











